

Connected with other core technologies is our application of machine learning. The aim of machine learning is to bundle, store and analyze machine and plant data. This enables the machine to independently generate knowledge based on its own experience. The predictive maintenance and service will be led into a new generation, as the analysis of very large amounts of data will be automated and solutions for new and previously unknown problems can be identified.
- Data will be collected, stored and analyzed
- Data-based predictions
- Probability calculation for incidents
- Automatic adaptation to data development
- Pattern recognition and analysis
- Process optimization
In order for machines and plants to learn and find solutions independently using the software, the technological basis must be created and suitable algorithms implemented. We use specially developed, highly optimized and GPU-supported machine learning algorithms to implement predictive maintenance functions.
The reason for using GPU is the performance improvement compared to CPU conversion. GPUs allows you to process many threads (tasks) in parallel and in real time on many cores. The few cores of a CPU are designed to optimize single-thread performance in contrast. In addition, there is a faster memory connection of the GPU. Machine learning via GPU is therefore more effective and more efficient, since tasks and data are processed more quickly and thus there is a considerable time advantage for predictive maintenance. Overall, GPU usage provides more resources for the calculation of complex simultaneous processes (matrix calculations) with a high computing speed and provides the optimal basis for our machine learning algorithms.
The algorithm uses the learned behavior of the system to evaluate the current state. The learned data is transferred to the IoT Gateway. The IoT Gateway uses the data to evaluate the status in real time. This evaluation is used to identify developments and deviations, so that countermeasures can be taken independently if problems occur depending on the state of the system.
A failure-safe system and high performance as well as optimum utilization of the machines used are elementary for machine users. The scope of machine learning covers the identification of deviations from the defined and learned sensor values, the detection of wear parts and the prediction of critical incidents. In any case, the aim of our machine learning solutions is to avoid machine failure, increase system performance, optimize maintenance intervals and minimize maintenance and repair costs.
In order to provide an optimal analysis via weMonitor, we have optimized our self-developed predictive maintenance algorithms especially for the use scenario for the evaluation of the machine condition. In line with our modular software and the associated technologies, customer-specific adjustment in machine learning is an important step towards an ideal result. Two algorithms form the basis for this:
Wear situations can be identified based on vibration data. In this case there are repeated temporal changes of relevant state variables. The attrition at this point is caused by the vibrations themselves.
In the course of time, there are always changes in the material, which also become visible in the vibration data. This development can be traced and learned by means of machine learning. It is now possible to refine the analysis and to recognize critical wear situations before they occur with this knowledge. In coordination with other core technologies, the vibration data is processed in real time. The relevant data are processed without delay and the machine learning algorithm is further refined during operation.
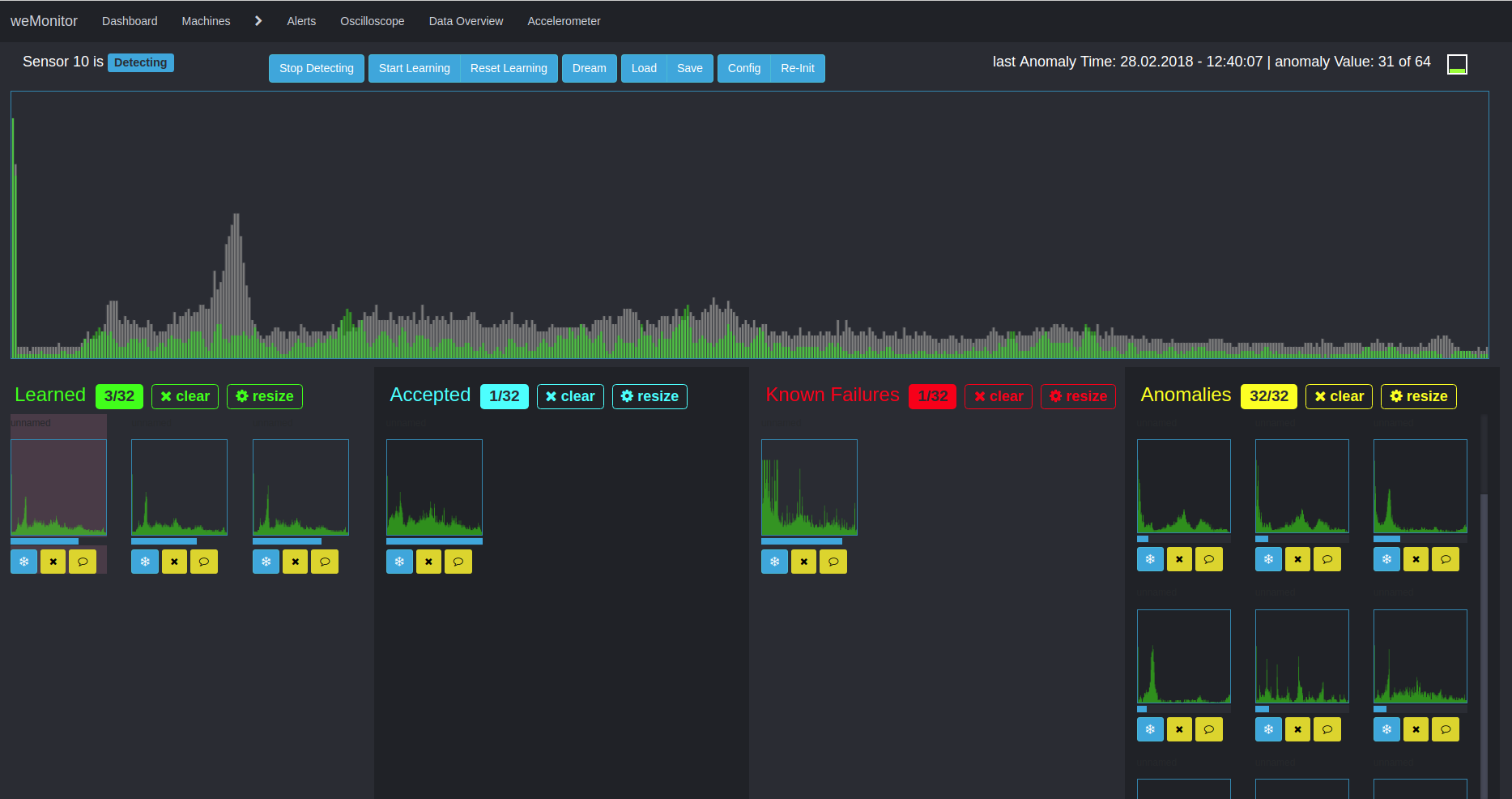
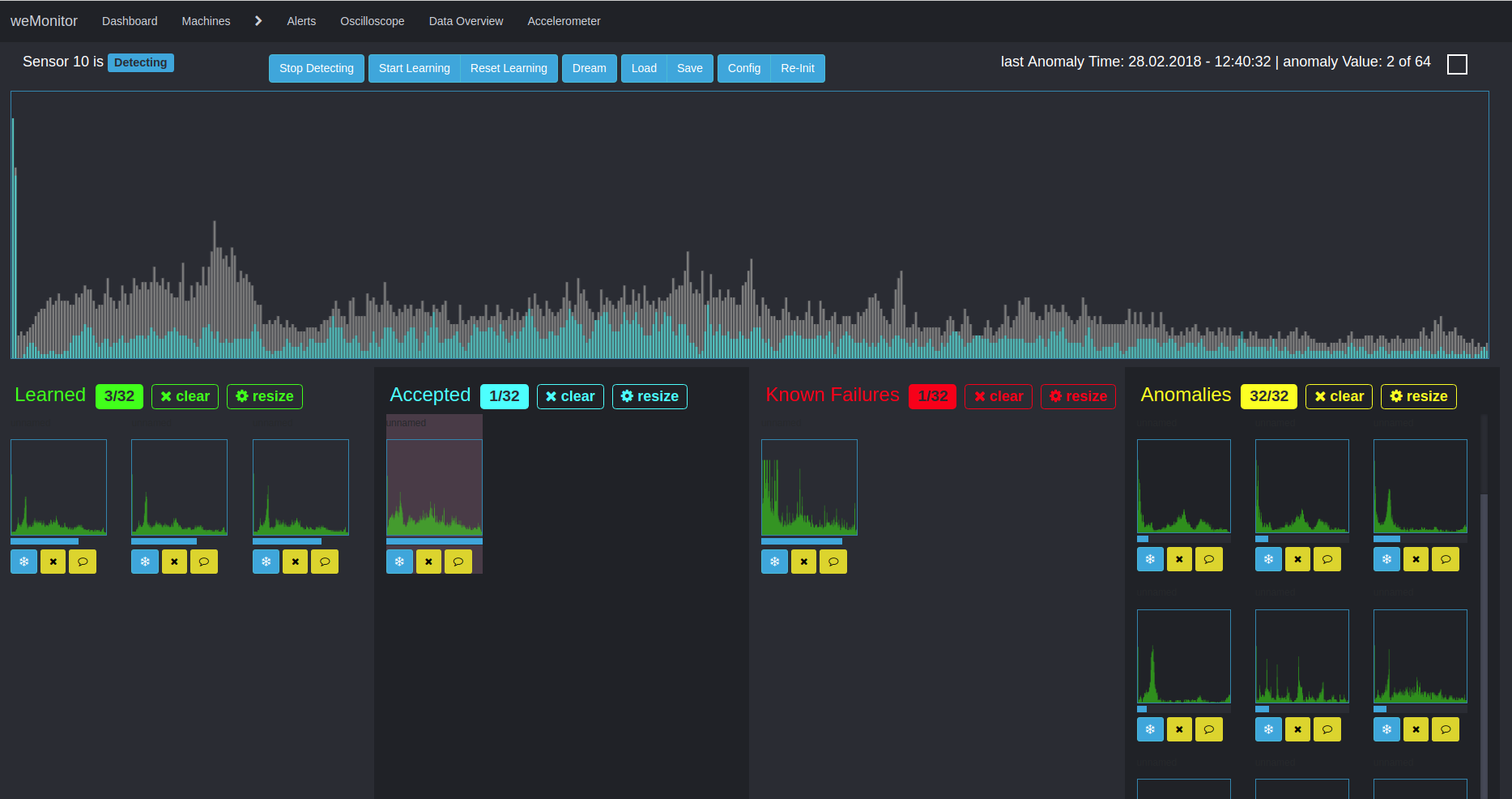
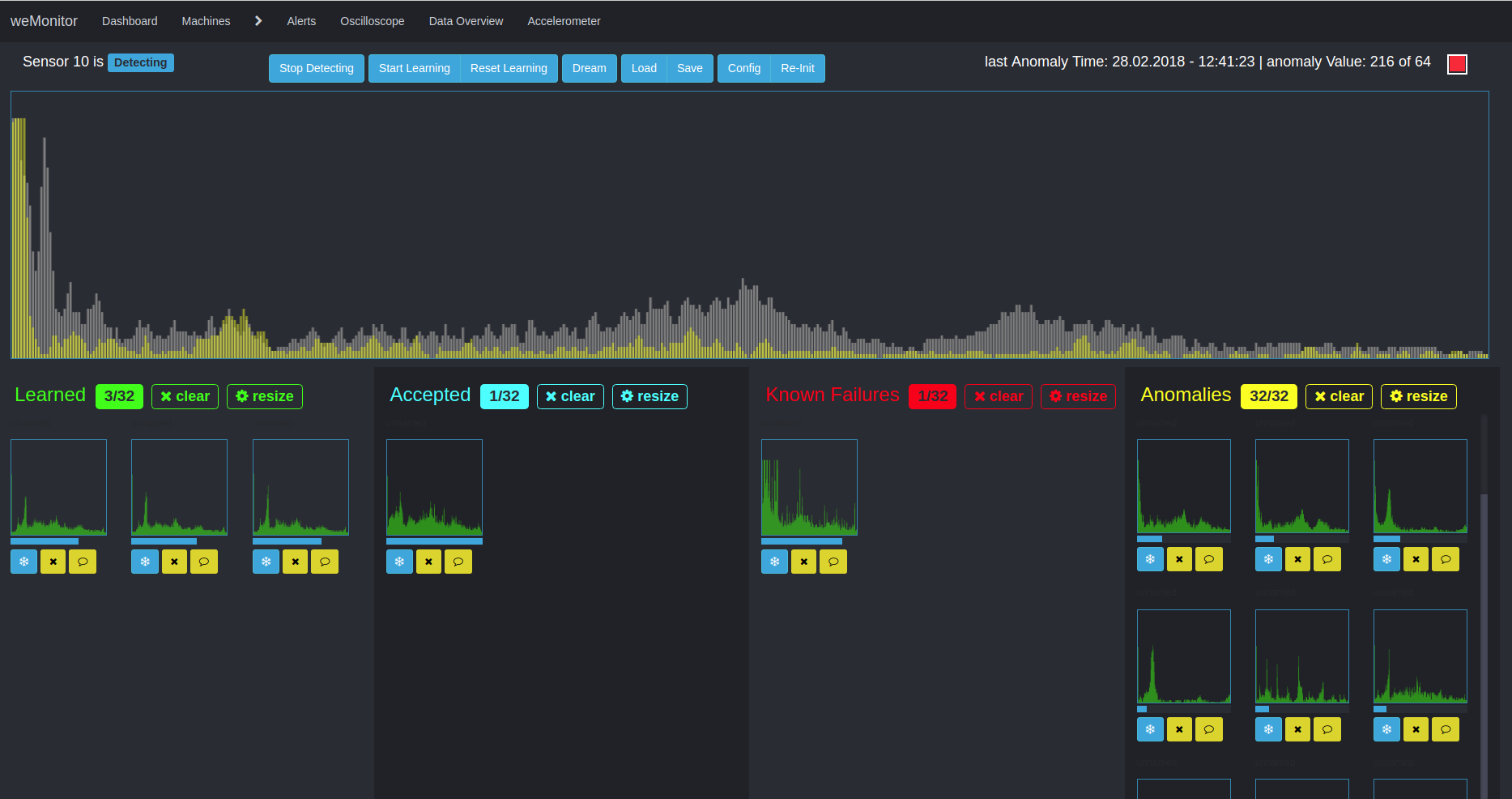
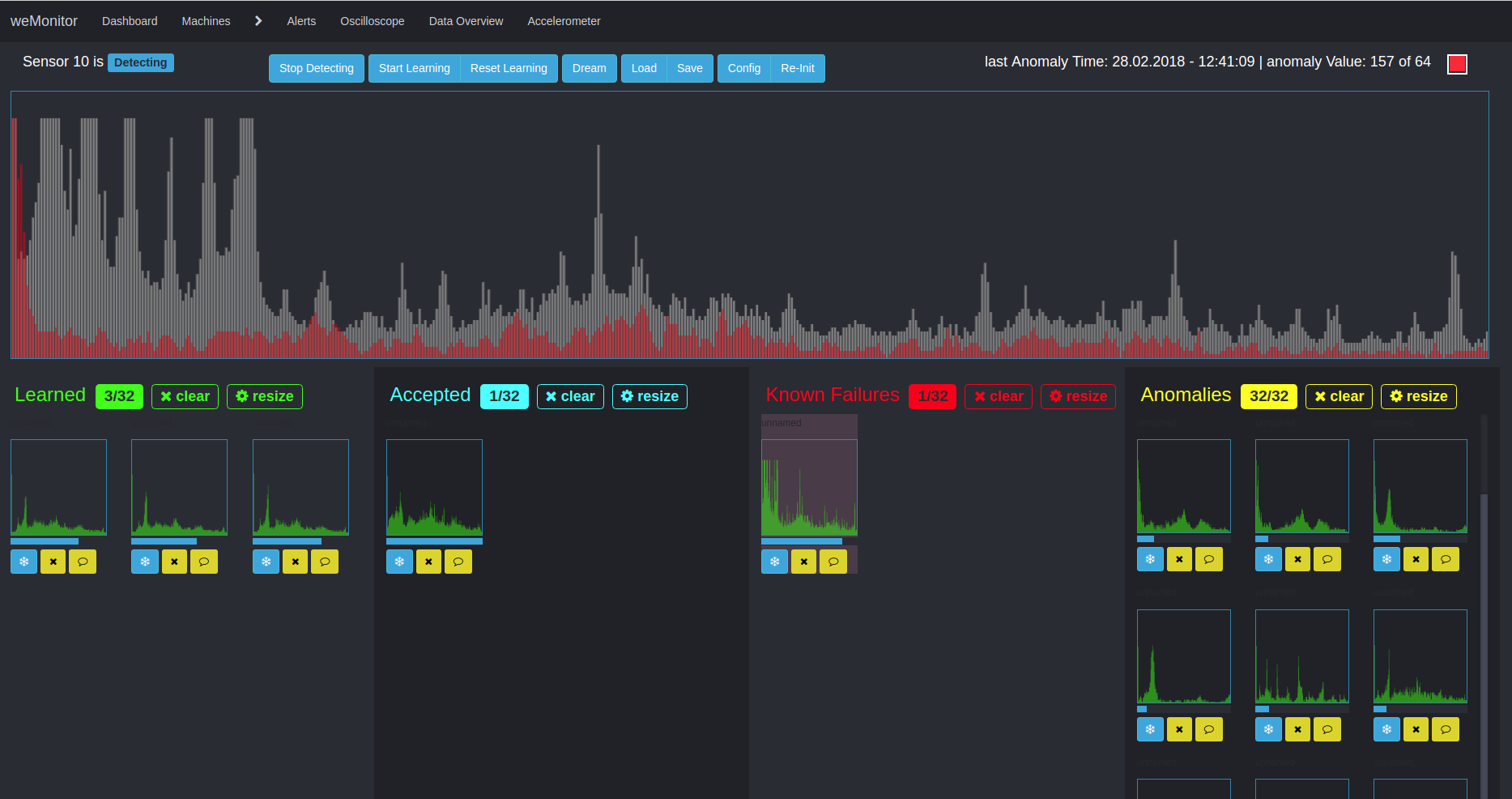
A second algorithm is used for multidimensional anomaly detection. This approach pursues the detection of deviations and irregularities in time series data. Due to the multidimensionality and the consideration of the overall system, the application of this method is complex in many ways. On the one hand, the interaction of different data and metrics must be considered. On the other hand, the alarm configuration can be a difficult. The reason for this is the complex definition of threshold values (for warning, error or emergency) in the context of measured sensor values.
The advantage of this approach lies in the consideration of anomalies in the overall system and the creation of links. The basis for further analysis in the learning phase is the creation of clusters to form similar structures within large amounts of data. A simplified application scenario would be, for example, the temperature deviation of a sensor from its normal state. Over time, the temperature moves within a "track" between the minimum, maximum and threshold values of the definition range. If there is a deviation, the temperature breaks out of this "trace". As a further factor, the condition of the machine as a whole must be taken into account: Is it doing any work or is it at a standstill? Based on this - and other influencing values - the algorithm analyses the overall situation. On the basis of the defined sensor values and the machine behavior, the algorithm learns to evaluate the overall system and to issue alarm messages in the event of deviations from the normal state. Here, too, the aim is to counteract and prevent cost-intensive machine failures and downtimes as well as expensive wear damage.
Due to its complexity, we support our users in every way to enable the best possible and most efficient anomaly detection.
Back to technology overview