

Verbunden mit weiteren Kerntechnologien ist unsere Anwendung des maschinellen Lernens. Ziel des Machine Learnings ist es, Maschinen- und Anlagendaten zu bündeln, zu speichern und zu analysieren. So wird es der Maschine ermöglicht, eigenständig Wissen zu erzeugen, welches auf selbst gesammelten Erfahrungen beruht. Die vorausschauende Wartung und Instandhaltung wird in eine neue Generation geführt, da die Analyse sehr großer Datenmengen automatisiert abläuft und sich entsprechende Lösungsansätze für neue sowie bisher unbekannte Probleme identifizieren lassen.
- Daten werden gesammelt, gespeichert und analysiert
- Datengestützte Vorhersagen
- Wahrscheinlichkeitsberechnung für Ereignisse
- Selbstständige Anpassung an die Datenentwicklung
- Mustererkennung und -analyse
- Prozessoptimierung
Damit Maschinen und Anlagen – mittels der eingesetzten Software – selbstständig lernen und Lösungen finden, müssen die technologischen Grundlagen geschaffen und passende Algorithmen implementiert werden. Um Predictive-Maintenance-Funktionen umzusetzen, verwenden wir eigens entwickelte, hochoptimierte und GPU-gestützte Machine-Learning-Algorithmen.
Grund für die GPU-Nutzung ist die Performanceverbesserung im Vergleich zur CPU-Umsetzung. GPUs erlauben es, auf sehr vielen Rechenkernen sehr viele Threads (Aufgaben) parallel und in Echtzeit zu bearbeiten. Im Gegensatz dazu sind die wenigen Kerne einer CPU auf die Optimierung der Single-Thread-Performance ausgelegt. Hinzu kommt eine schnellere Speicheranbindung der GPU. Für die vorausschauende Instandhaltung ist Machine Learning via GPU daher effektiver und effizienter, da Aufgaben und Daten schneller be- und verarbeitet werden und so ein erheblicher Zeitvorteil besteht. Insgesamt stellt die GPU-Nutzung mehr Ressourcen für die Berechnung komplexer simultaner Prozesse (Matrixberechnungen) mit einer hohen Rechengeschwindigkeit zur Verfügung und bietet damit die optimale Basis für unsere Machine-Learning-Algorithmen.
Das erlernte Systemverhalten nutzt der Algorithmus, um den aktuellen Zustand zu bewerten. Dazu werden die erlernten Daten auf das IoT Gateway übertragen. Dieses nutzt die Daten, um eine Zustandsbewertung in Echtzeit vorzunehmen. Anhand dieser Bewertung werden – je nach Systemzustand – Entwicklungen und Abweichungen erkannt, so dass bei Problemen Gegenmaßnahmen ergriffen werden können.
Elementar für Maschinennutzer ist sowohl ein ausfallsicherer Betrieb und die Sicherstellung einer hohen Leistung als auch eine optimale Auslastung der eingesetzten Maschinen. Die Bandbreite des Machine Learnings erstreckt sich über die Identifizierung von Abweichungen der definierten und erlernten Sensorwerte, das Erkennen von Verschleißteilen und dem Vorhersagen kritischer Ereignisse. In jedem Fall ist der Anspruch unserer Machine-Learning-Lösungen, einen Maschinenausfall zu vermeiden, die Anlagenleistung zu steigern, Wartungsintervalle zu optimieren sowie Instandhaltungs- und Reparaturkosten zu minimieren.
Um eine optimale Analyse via weMonitor zur Verfügung zu stellen, haben wir unsere selbst entwickelten Predictive-Maintenance-Algorithmen speziell auf das Anwendungsszenario zur Bewertung des Maschinenzustandes optimiert. Entsprechend unserer modularen Software und den damit verknüpften Technologien ist für uns auch im Machine Learning die kundenindividuelle Anpassung ein wichtiger Schritt für ein ideales Ergebnis. Die Grundlage hierfür bilden zwei Algorithmen:
Verschleißsituationen lassen sich anhand von Schwingungsdaten identifizieren. In diesem Fall kommt es zu wiederholten zeitlichen Veränderungen von relevanten Zustandsgrößen. Der Verschleiß entsteht an dieser Stelle durch die Schwingungen selbst.
Im Zeitverlauf ergeben sich daher immer wieder Veränderungen am Material, welche auch in den Schwingungsdaten deutlich werden. Mittels Machine Learning kann diese Entwicklung nachvollzogen und so angelernt werden. Mit dem Wissen ist es nun möglich, die Analyse zu verfeinern und kritische Verschleißsituationen zu erkennen, bevor sie auftreten. In Abstimmung mit anderen Kerntechnologien erfolgt die Verarbeitung der Schwingungsdaten in Echtzeit. Die relevanten Daten werden so ohne Verzögerung aufbereitet und der Machine-Learning-Algorithmus während des Betriebs weiter verfeinert.
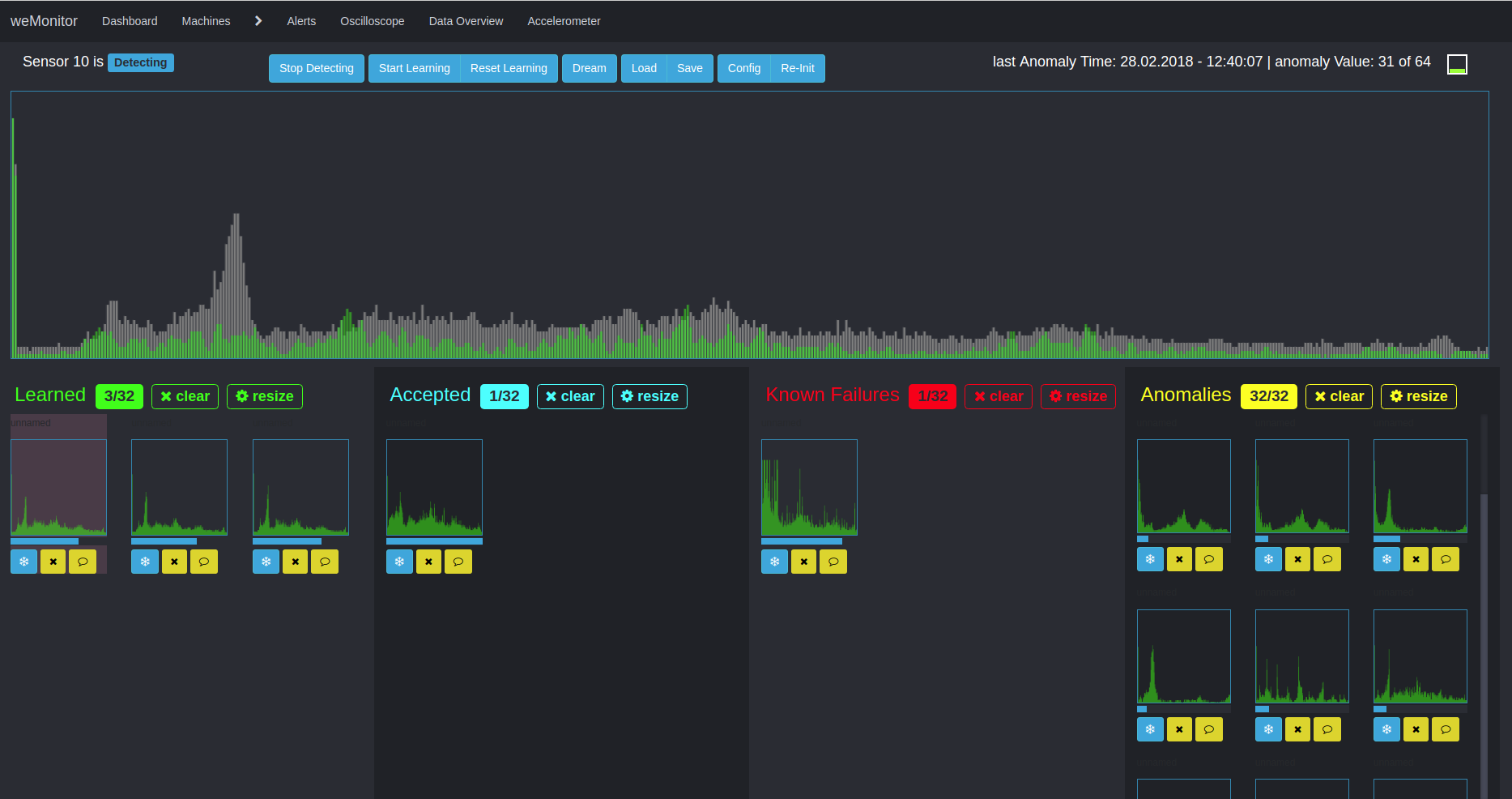
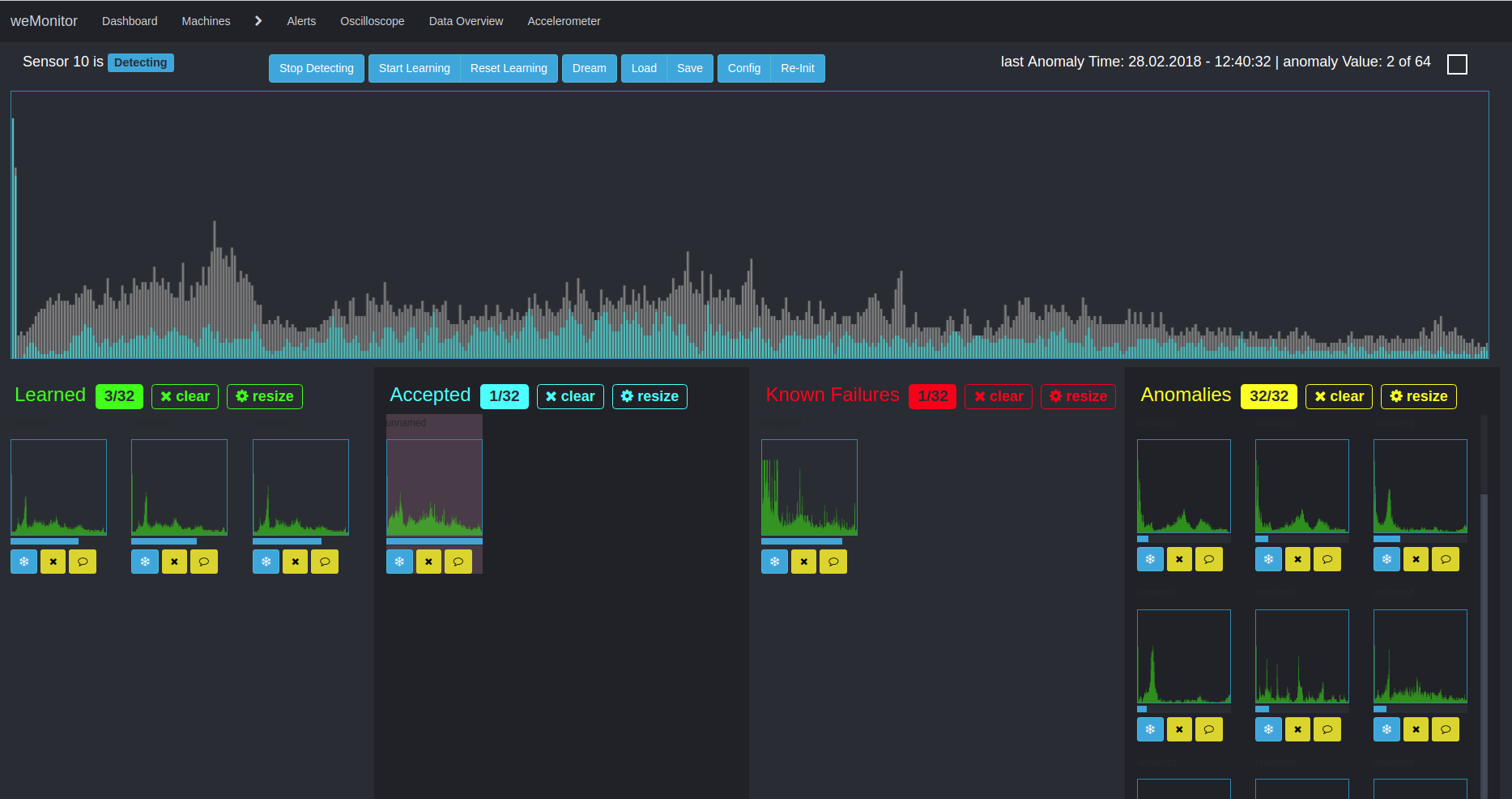
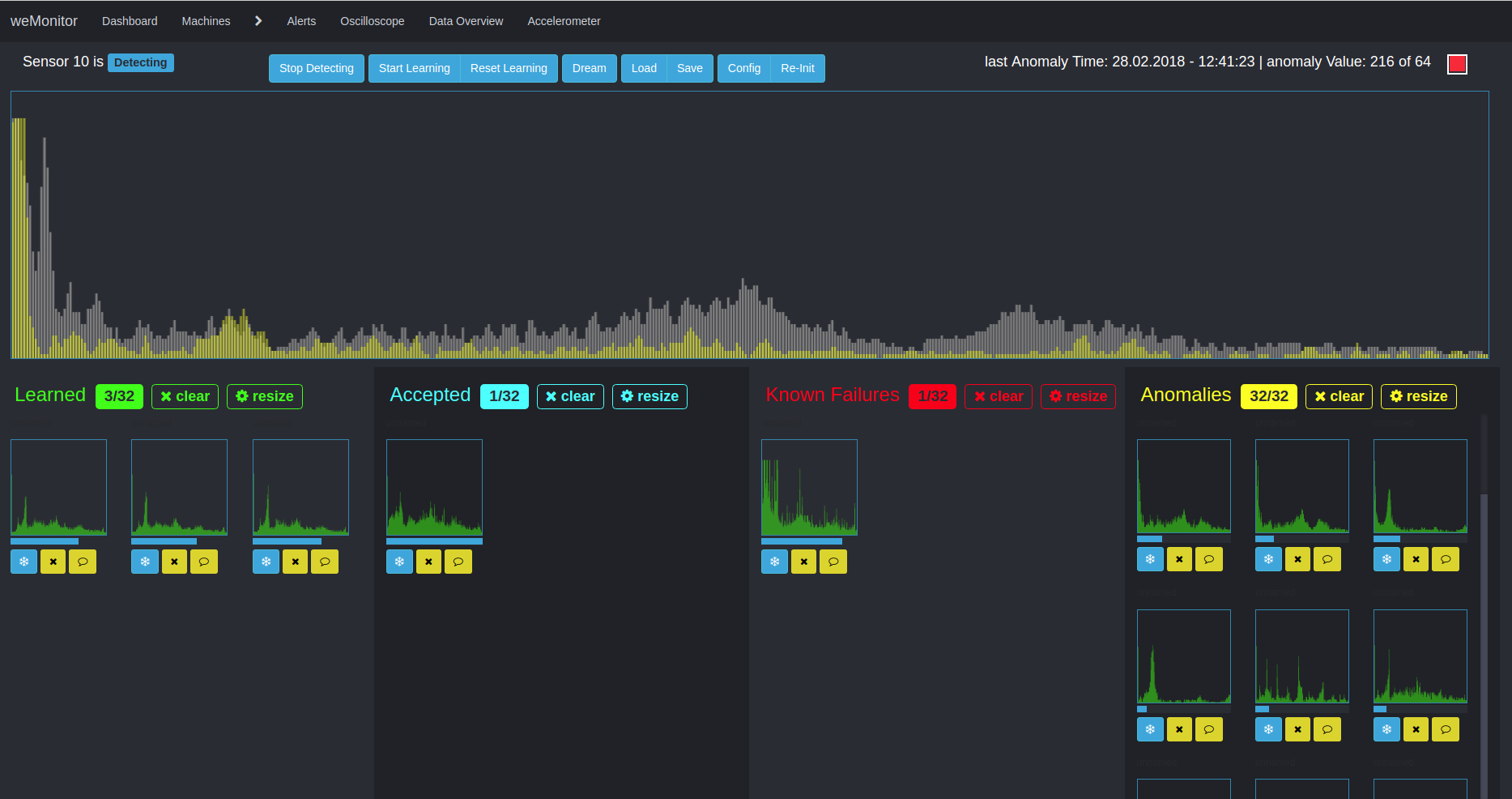
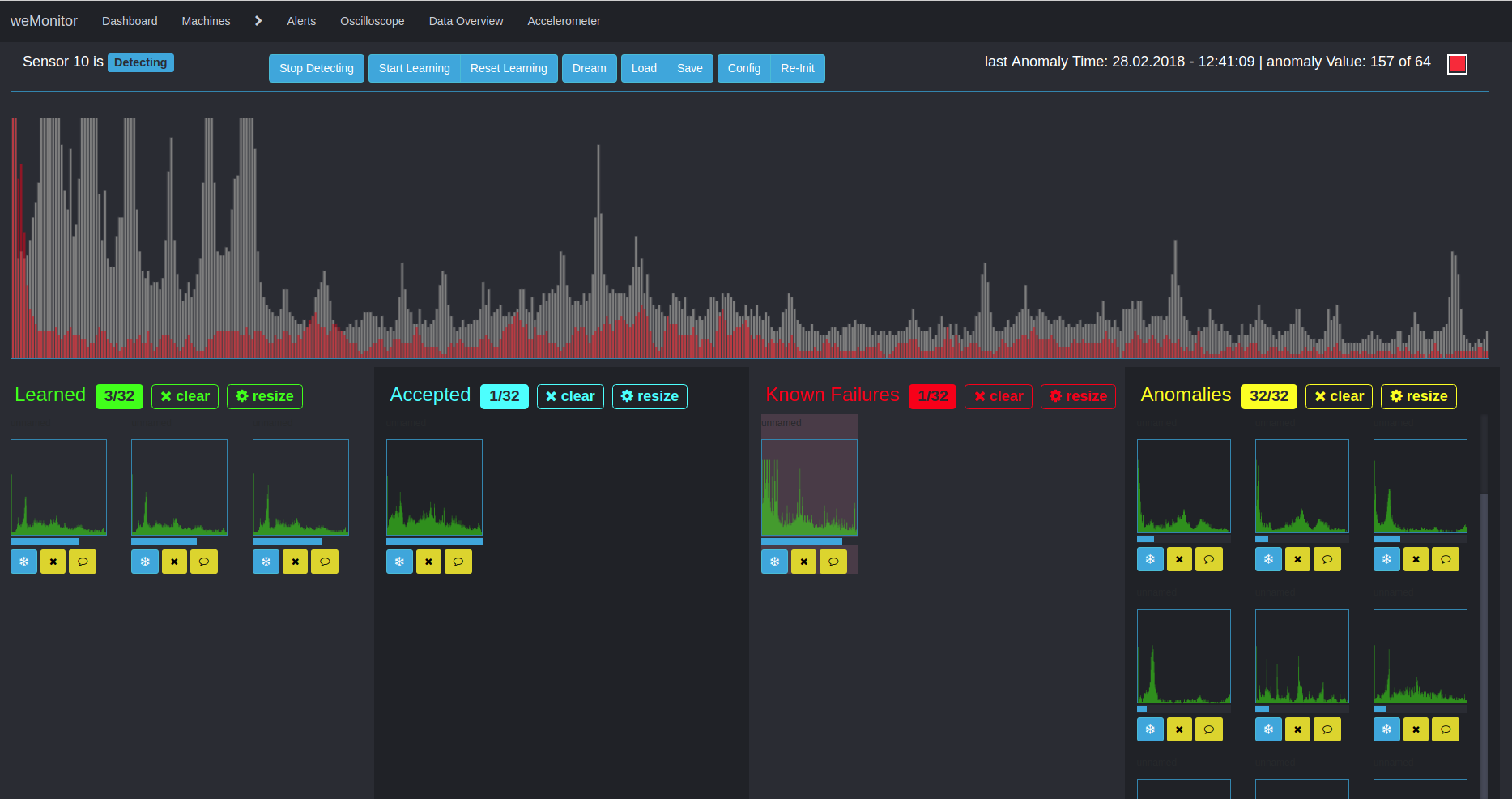
Ein zweiter Algorithmus kommt für die multidimensionale Anomaly Detection zum Einsatz. Dieser Ansatz verfolgt die Entdeckung von Abweichungen und Unregelmäßigkeiten in Zeitreihendaten. Aufgrund der Multidimensionalität und der Berücksichtigung des Gesamtsystems ist die Anwendung dieses Verfahrens komplex in vielfacher Hinsicht. Zum einen muss die Interaktion verschiedener Daten und Metriken bedacht werden. Zum anderen kann die Alarmkonfiguration eine Schwierigkeit darstellen. Der Grund dafür ist die aufwendige Definition von Schwellenwerten (für Warnung, Fehler oder Notfall) im Kontext gemessener Sensorwerte.
Der Vorteil dieses Ansatzes liegt in der Betrachtung der Anomalien im Gesamtsystem und dem Herstellen von Verknüpfungen. Grundlage für die weitere Analyse ist in der Lernphase das Schaffen von Clustern, um Ähnlichkeitsstrukturen innerhalb großer Datenmengen herauszubilden. Ein vereinfachtes Anwendungsszenario wäre beispielsweise die Temperaturabweichung eines Sensors vom Normalzustand. Im Zeitverlauf bewegt sich die Temperatur innerhalb einer "Spur" zwischen den Minimal,- Maximal und Schwellenwerten des Definitionsbereichs. Kommt es zu einer Abweichung, bricht die Temperatur aus dieser "Spur" aus. Als weiterer Faktor muss hier jedoch beachtet werden, in welchem Zustand sich die Maschine als Ganzes befindet: Verrichtet sie Arbeit oder befindet sie sich im Stillstand? Anhand dessen – und weiterer Einflusswerte – analysiert der Algorithmus die Gesamtsituation. Der Algorithmus erlernt anhand der definierten Sensorwerte und des Maschinenverhaltens, das Gesamtsystem zu bewerten und bei Abweichungen vom Normalzustand, Alarmmeldungen auszugeben. Ziel ist auch hier, kostenintensive Maschinendefekte und -stillstände sowie teure Verschleißschäden entgegenzuwirken und vorzubeugen.
Aufgrund der Komplexität unterstützen wir unsere Anwender in jeglicher Hinsicht, um eine bestmögliche und effiziente Anomaly Detection zu ermöglichen.
Zurück zur Technologieübersicht